The Air Quality egg monitors local Co, No2, Temperature and Humidity levels. Reading from the Air Quality Egg can be shared and compared on a web-based crowd sourced dashboard at: http://airqualityegg.com
We're very pleased to be the UK/Europe distributor for the Air Quality Egg and air quality Arduino Shields on behalf of Wicked Device.
Air quality is important to our health and something which is easily overlooked. Although the Air Quality Egg is not strictly an energy monitor it's very similar hardware and web-connectivity wise. Over time we would like to make it possible to integrate the Air Quality Eggs sensors it into an existing OpenEnergyMonitor system.

The project was funded as part of a successful Kickstarter (actually once of the 20 top kickstarter projects of 2012!), the Air Quality Eggs are manufactured in the US by Wicked Device.
If your familiar with the Arduino IDE we recommend you 'crack-open' the base-station egg and connect the USB to UART cable (included) and open up an Arduino IDE terminal window (115200 baud) to view a verbose output of the setup process. Here's an example terminal output from a successfully connected egg:
Air Quality Egg forum: http://osqa.wickeddevice.com/
Google Group: https://groups.google.com/forum/?fromgroups#!forum/airqualityegg

The project was funded as part of a successful Kickstarter (actually once of the 20 top kickstarter projects of 2012!), the Air Quality Eggs are manufactured in the US by Wicked Device.
Hardware
Hardware wise the Air Quality Egg is two NanodeRF SMT's, one with an Air Quality Egg Sensor Shield (temperature, humidity, carbon monoxide and nitrous dioxide sensors) + mini fan and the other with an Ethernet controller and an RGB status LED which illuminates the egg housing. The sensor egg should be located outdoors (but undercover) and the base-station egg plugs into your home Internet router. The units communicated via 433Mhz RFM12B.
The two eggs (transmitter and base-station) collectively consumer 4W of power.
 |
| Cracking the egg open - eggs from OpenEnergyMonitor shop will include UK / Euro plugs |
Software
Firmware - The AQE is Arduino compatible. It uses many of the same libraries and a Nanode emonBase (e.g JeeLib and EtherCard). The AQE can easily be re-programmed with a USB to UART cable (included) and Arduino IDE. All the firmware is up on GitHub. All the AQE's from OpenEnergyMonitor will be shipped with the latest firmware (V1.03 as of 8th Feb 2013).
IoT Cloud - Cosm is used as the data store for the AQE. A neat open-source Ruby web-application has been written to display a crowd sourced web-dashboard with a nice Google map showing egg monitoring locations.
 |
| http://airqualityegg.com/ - let's get some more European eggs activated! |
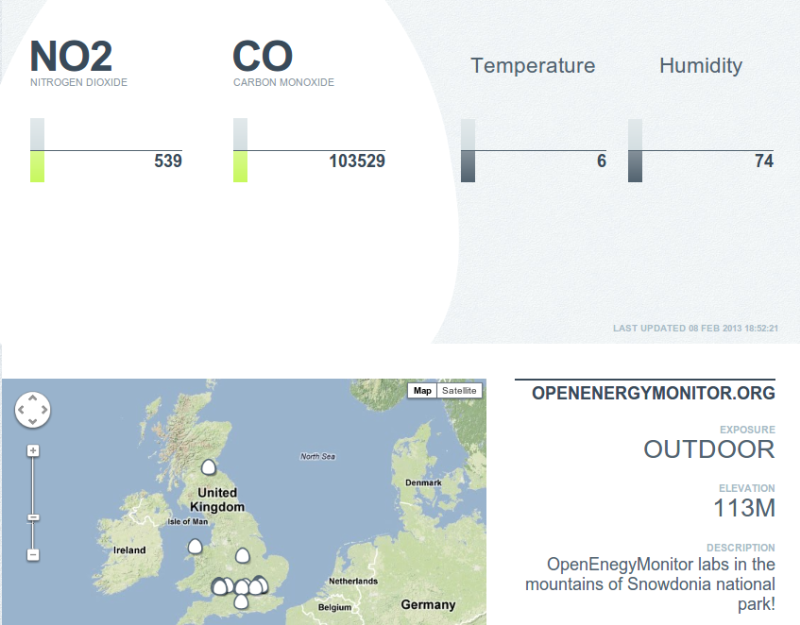 |
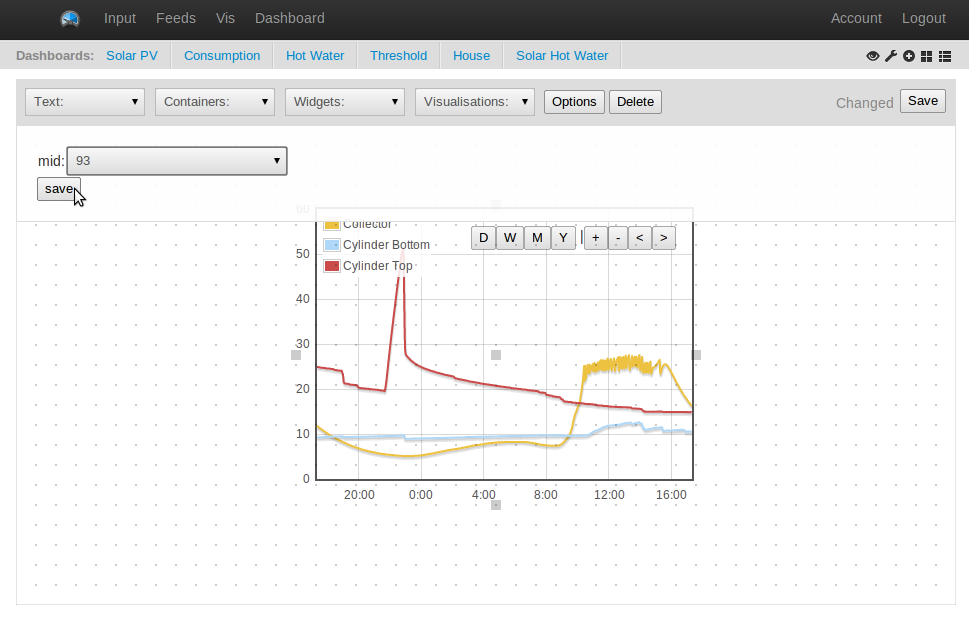
| Example Air Quality Egg Readings from the OpenEnergyMonitor labs, readings may be in-correct. Sensors take a few days to 'burn-in'. See here for the live version: http://airqualityegg.com/egg/103153 |
Setup
Follow the setup instructions on: http://aqe.wickeddevice.com/?page_id=39
In summary setup is as simple as:
- Head to http://airqualityegg.com/ and enter the serial number on the AQE box
- Plug in the base station - watch for LED illumination sequence (green LED) to confirm successfully connection (or connect FTDI on baud 115200 for more verbose confirmation)
- Pair sensor egg to base station by un-plugging the base station, then plugging it back-in then connecting the sensor egg when the base station glows yellow. Base egg will cycle through a number of colours to confirm pairing.
- Deploy sensor egg somewhere in the open air (but undercover) within 100ft of the base
 |
| Base-egg LED colour status debugging from Wicked Device Blog |
Stack: 271
[Air Quality Egg - Base Egg - v1.03]
Unit Address: xx_xx_YOUR SERIAL NUMBER HERE_xx_xx
3070 Received Packet During Pairing
85 0 4 163 55 182 217 0
Pairing Event Count: 1
8159 Received Packet During Pairing
85 0 4 163 55 182 217 0
Pairing Event Count: 2
Pairing complete
Egg Serial #: 00:04:a3:37:b6:d9
IP: 192.168.1.102
GW: 192.168.1.254
DNS: 192.168.1.254
Stack: 191
SRV: 216.52.233.121
Previously provisioned
Packet Received @ 107604
Packet Type: 33
Remote Firmware Version: 3
Remote Station Address: 00_04_A3_37_BB_97
Source Sensor Address: 00_04_A3_37_BB_97
Sensor Index: 0
Sensor Type: Temperature
Sensor Units: deg C
Sensor Value: 11
Preparing stash
Sending data to Cosm
Data sent
>>> RESPONSE RECEIVED ---
[Air Quality Egg - Base Egg - v1.03]
Unit Address: xx_xx_YOUR SERIAL NUMBER HERE_xx_xx
3070 Received Packet During Pairing
85 0 4 163 55 182 217 0
Pairing Event Count: 1
8159 Received Packet During Pairing
85 0 4 163 55 182 217 0
Pairing Event Count: 2
Pairing complete
Egg Serial #: 00:04:a3:37:b6:d9
IP: 192.168.1.102
GW: 192.168.1.254
DNS: 192.168.1.254
Stack: 191
SRV: 216.52.233.121
Previously provisioned
Packet Received @ 107604
Packet Type: 33
Remote Firmware Version: 3
Remote Station Address: 00_04_A3_37_BB_97
Source Sensor Address: 00_04_A3_37_BB_97
Sensor Index: 0
Sensor Type: Temperature
Sensor Units: deg C
Sensor Value: 11
Preparing stash
Sending data to Cosm
Data sent
>>> RESPONSE RECEIVED ---
Future Development
Wicked Device are actively developing the air quality sensors. Most recent is a dust-sensor add-on board.
We would love to make the Air Quality egg sensors more integrated into the OpenEnergyMonitor system, it would be cool to be able to add an air monitor sensor to an energy monitoring system using a Raspberry Pi with a RFM12Pi as the base station.
The community crowd sourcing aspect of the AQE using Cosm as the data store has the obvious advantages of being able to easily share and compare air quality data (which is what the project is all about). However it would also be cool to get the data into emoncms for better graphing and analysis. I would love to see how the air quality date fluctuates over the days/months/year(s).
Community / Troubleshooting / More info
As always you are most welcome to post on the active and friendly OpenEnergyMonitor forums. However the Air Quality Egg is quite a new thing for us, more relevant support might be better obtained from:Air Quality Egg forum: http://osqa.wickeddevice.com/
Google Group: https://groups.google.com/forum/?fromgroups#!forum/airqualityegg
Other Sources of Information:
- Wicked Device Air Quality Egg homepage: http://aqe.wickeddevice.com
- Community wiki: http://airqualityegg.wikispaces.com/AirQualityEgg
- Github Source code & PCB cad files: http://github.com/jmsaavedra/Air-Quality-Egg
- Google Doc with Fimrware Documentation
- Wicked Device Blog: http://aqe.wickeddevice.com/blog.wickeddevice.com