Removing redundant datapoints - part 1
As I mentioned before another idea for reducing disk use is compression by removing redundant datapoints. Describing our plot with the least possible number of datapoints. Before energy monitoring I first learnt programming writing some basic 3d games and physics simulations using OpenGL, I was always fascinated by trying to create 3d landscapes, one of the techniques used to generated large landscapes is called level-of-detail terrains where you increase the polygon count where there is lots of detail I.e a mountain ridge or reduce the polygon count where there isnt ie a flat plain. I've been wondering for a while whether a similar approach could be taken to describe timeseries data so we increase the datapoint rate where there is a big change (ie when the kettle, light, fridge goes on) so that we get that event exactly at the right point in time and reduce the rate when not much is happening.
I tried to do something along these lines a few years back where the hardware would only post to the server on a step change in the power signal, the code is still up here as part of the appliance inference work I was experimenting with: http://openenergymonitor.org/emon/buildingblocks/appliance-inference
The problem was that it was failing when events happened too frequently, ie a thermostat controlled cooker cycling on and off. The event detection algorithm relied upon two 5 datapoint segments next to each other, when the difference between the average of the segments where larger than a threshold an event would be registered. A 10 datapoint segment spanning ~ 100s at 10s per datapoint or 50 seconds at 5s is too large and will miss events that happen to frequently. The other problem with this approach is that it wont work for temperature data which is more a change of gradient than power data steps.
Anyway with the problem of large emoncms disk space demand I have been thinking about this idea again. Could it be used to reduce disk space use significantly without loosing vital timing on events that would happen by just reducing the post interval rate. I had a good conversation with the guys at houseahedron https://twitter.com/Housahedronwho came to visit last week about this, they had been thinking along similar lines and saw parallels with an approach used in path plotting, they took a couple of example datasets back with them to see if they can find a way to parse it.
The screenshot below shows the solar hot water pump coming on for 40 mins at the beginning of a bright sunny day. The raw data would use 720 datapoints at a 10s post interval to describe the plot. Overlayed on the raw data plot I have drawn a second line that only has datapoints where needed to keep the standard deviation between the lines roughly within an acceptable limit, in this case 10 datapoints seems to be enough to do this. If this kind of datapoint reduction rate is typical then a 60Mb mysql table with the current emoncms implementation might only take up 0.83Mb of space per year.

Zooming in a bit, rather than 270 datapoints, this could be described with 8. (at this datapoint reduction rate 60Mb would compress to ~1.8Mb)
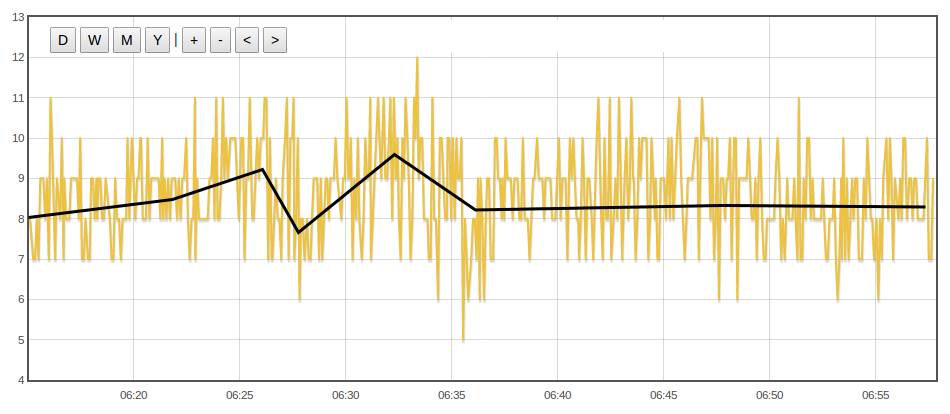
In addition to reducing disk space, it may be possible to use this technique to increase the resolution of our measurement as we are oversampling in regions where there are no large changes
This atmel appnote describes how to use oversampling and decimation to achieve greater measurement resolution:
I think there are two main development questions facing this idea:
- Can a good enough algorithm be developed to compress the data while retaining the detail we want.
- What are the implications for data query speeds?
The above said, I think timestore looks like the leading solution at the moment for data storage and fast query speeds. With timestore we can achieve an 80% reduction in disk space demand from 60Mb per 10s feed per year to 12.3 Mb, this would reduce the disk space use on emoncms.org from 47GB to 9.6GB, disk space use would increase at 20GB per year (costing £96 per 20GB stored inc backup instead of £480/year) and most of its already there in terms of implementation.
It might just be interesting to explore the datapoint reduction idea in parallel to see if further disk space reductions can be achieved but without sacrificing on query speeds which is the open question. If feeds could be compressed to 1.8Mb from 60Mb emoncms.org disk use would shrink from 47GB to 1.2GB and disk space would increase at a rate of 2.6 GB a year which would make server disk space costs pretty negligible.
To engage in discussion regarding this post, please post on our Community Forum.